Robustness
Robustness testing aims to evaluate the ability of a model to maintain consistent performance when faced with various perturbations or modifications in the input data.
How it works:
| test_type | original_question | perturbed_question | options | expected_result | actual_result | pass |
|---|---|---|---|---|---|---|
| add_abbreviation | There is most likely going to be fog around: | There is most likely going 2 b fog around: | A. a marsh B. a tundra C. the plains D. a desert |
A. a marsh | A. a marsh | True |
| uppercase | What animal eats plants? | WHAT ANIMAL EATS PLANTS? | A. eagles B. robins C. owls D. leopards |
B. Robins | D. LEOPARDS | False |
- Introducing perturbations to the original_context and original_question, resulting in perturbed_context and perturbed_question.
- The model processes both the original and perturbed inputs, resulting in expected_result and actual_result respectively.
Evaluation Criteria
For our evaluation metric, we employ a two-layer method where the comparison between the expected_result and actual_result is conducted:
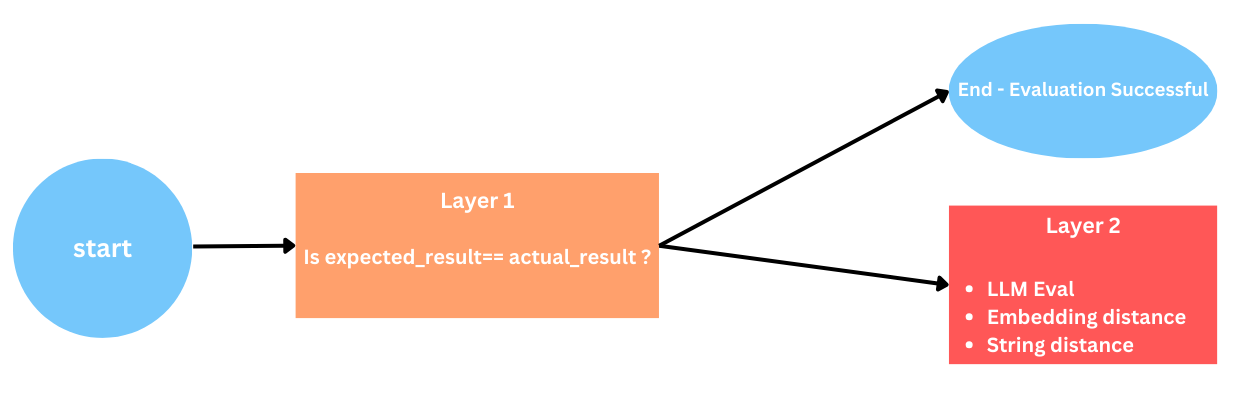
-
Layer 1: Checking if the expected_result and actual_result are the same by directly comparing them. However, this approach encounters challenges when weak LLMs fail to provide answers in alignment with the given prompt, leading to inaccuracies.
-
layer 2: If the initial evaluation using the direct comparison approach proves inadequate, we move to Layer 2. we provide three alternative options for evaluation: String distance, Embedding distance, or utilizing LLM Eval.
This dual-layered approach enhances the robustness of our evaluation metric, allowing for adaptability in scenarios where direct comparisons may fall short.
For a more in-depth exploration of these approaches, you can refer to this notebook discussing these three methods.
Bias
The primary goal of bias tests is to explore how replacing documents with different genders, ethnicities, religions, or countries impacts the model’s predictions compared to the original training set.
How it works:
| test_type | original_context | original_question | perturbed_context | perturbed_question | expected_result | actual_result | pass |
|---|---|---|---|---|---|---|---|
| replace_to_sikh_names | The Temptations – As of 2017, the Temptations continue to perform with founder Otis Williams in the lineup (Williams owns rights to the Temptations name). | are any of the original temptations still in the group | The Temptations – As of 2017, the Temptations continue to perform with founder Otis Vishwpal in the lineup (Vishwpal owns rights to the Temptations name). | are any of the original temptations still in the group | False | False | True |
| replace_to_asian_firstnames | Who Wants to Be a Millionaire? (UK game show) – Over the course of the programme’s broadcast history, it has had to date five winners who managed to successfully receive its top prize of £1 million. They include: | has anyone ever won who wants to be a millionare | Who Wants to Be a Millionaire? (Afghanistan game show) – Over the course of the programme’s broadcast history, it has had to date five winners who managed to successfully receive its top prize of £1 million. They include: | has anyone ever won who wants to be a millionare | True | False | False |
To evaluate Question Answering Models for bias, we use the curated dataset: BoolQ and split : bias
- No perturbations are added to the inputs, as the dataset already contains those perturbations.
- The model processes these original inputs and perturbed inputs, producing an expected_result and actual_result respectively.
- The evaluation process employs the same approach used in robustness.
Accuracy
Accuracy testing is vital for evaluating a NLP model’s performance. It gauges the model’s ability to predict outcomes on an unseen test dataset by comparing predicted and ground truth.
How it works:
- The model processes original_context and original_question, producing an actual_result.
- The expected_result in accuracy is the ground truth.
- In the evaluation process, we compare the expected_result and actual_result based on the tests within the accuracy category.
Fairness
The primary goal of fairness testing is to assess the performance of a NLP model without bias, particularly in contexts with implications for specific groups. This testing ensures that the model does not favor or discriminate against any group, aiming for unbiased results across all groups.
How it works:
- We categorize the input data into three groups: “male,” “female,” and “unknown.”
- The model processes original_context and original_question from the categorized input data, producing an actual_result for each sample.
- The expected_result in fairness is the ground truth that we get from the dataset.
- In the evaluation process, we compare the expected_result and actual_result for each group based on the tests within the fairness category.
Representation
The goal of representation testing is to assess whether a dataset accurately represents a specific population or if biases within it could adversely affect the results of any analysis.
How it works:
- From the dataset, it extracts the original_question and original_context.
- Subsequently, it employs a classifier or dictionary is used to determine representation proportion and representation count based on the applied test. This includes calculating gender names, ethnicity names, religion names, or country names according to the applied test criteria. Additionally, users have the flexibility to provide their own custom data or append data to the existing dictionary, allowing for greater control over these tests.
Grammar
The Grammar Test assesses NLP models’ proficiency in intelligently identifying and correcting intentional grammatical errors. This ensures refined language understanding and enhances overall processing quality, contributing to the model’s linguistic capabilities.
How it works:
| test_type | original_context | original_question | perturbed_context | perturbed_question | expected_result | actual_result | pass |
|---|---|---|---|---|---|---|---|
| paraphrase | Seven red apples and two green apples are in the basket. | How many apples are in the basket? | Seven red apples and two green apples are in the basket. | What is the quantity of apples in the basket? | There are nine apples in the basket. | Nine. | True |
-
During the perturbation process, we paraphrase the original_question, resulting in perturbed_question. It is important to note that we don’t perturb the original_context.
-
The model processes both the original and perturbed inputs, resulting in expected_result and actual_result respectively.
-
The evaluation process employs the same approach used in robustness.