Proportional Augmentation
Proportional Augmentation is based on robustness and bias tests. It can be used to improve data quality by employing various testing methods that modify or generate new data based on a set of training data.

The .augment() function takes the following parameters:
training_data(dict): (Required) Specifies the source of the original training data. It should be a dictionary containing the necessary information about the dataset.save_data_path(str): (Required) Name of the file to store the augmented data. The augmented dataset will be saved in this file.export_mode(str): (Optional) Specifies how the augmented data should be exported. The possible values are:- inplace: Modifies the list of samples in place.
- add: Adds new samples to the input data.
- transformed: Exports only the transformed data, excluding different untransformed samples.
custom_proportions(dict): (Optional) custom_proportions is a dictionary with augmentation on test type as key and proportion as value. The proportion is the percentage of the test cases that will be augmented with the given augmentation type. By default ,pass_rateandminimum_pass_ratefrom the report for the provided model to calculate the propotion
Proportion Increase Rates
The following table outlines the classification of proportion increase rates based on the comparison of the minimum pass rate with the pass rate figures (“x”).
| Range | Assigned Value | Interpretation |
|---|---|---|
| x ≥ 1 | Undefined | Not applicable |
| 0.9 ≤ x < 1 | 0.05 | Moderate increase |
| 0.8 ≤ x < 0.9 | 0.1 | Relatively higher increase |
| 0.7 ≤ x < 0.8 | 0.2 | Notable increase |
| x < 0.7 | 0.3 | Default increase rate |
custom_proportions = {
'add_typo':0.3,
'lowercase':0.3
}
data_kwargs = {
"data_source" : "conll03.conll",
}
h.augment(
training_data = data_kwargs,
save_data_path ="augmented_conll03.conll",
custom_proportions=custom_proportions,
export_mode="transformed")
This method applies perturbations to the input data based on the recommendations from the Harness report. This augmented dataset can then be used to retrain a model so as to make it more robust than its previous version.
Passing a Hugging Face Dataset for Augmentation
For Augmentations, we specify the HuggingFace data input in the following way:
custom_proportions = {
'add_ocr_typo':0.3
}
data_kwargs = {
"data_source" : "glue",
"subset": "sst2",
"feature_column": "sentence",
"target_column": "label",
"split": "train",
"source": "huggingface"
}
h.augment(
training_data = data_kwargs,
save_data_path ="augmented_glue.csv",
custom_proportions=custom_proportions,
export_mode="add",
)
Templatic Augmentations
Templatic Augmentation is a technique that allows you to generate new training data by applying a set of predefined templates to the original training data. The templates are designed to introduce noise into the training data in a way that simulates real-world conditions.
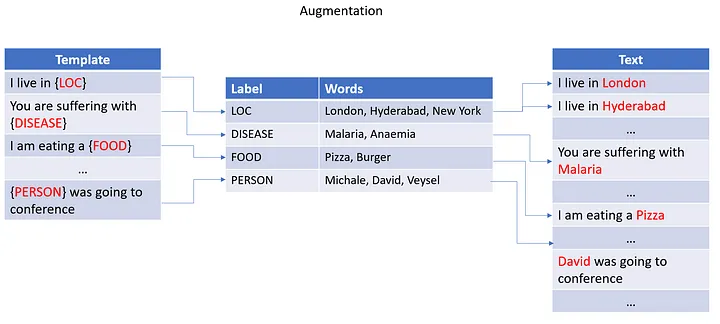
Templatic augmentation is controlled by templates to be used with training data to be augmented. The augmentation process is performed by the augment() method of the Harness class.
template = ["The {ORG} company is located in {LOC}", "The {ORG} company is located in {LOC} and is owned by {PER}"]
The .augment() function takes the following parameters:
training_data(dict): (Required) Specifies the source of the original training data. It should be a dictionary containing the necessary information about the dataset.save_data_path(str): (Required) Name of the file to store the augmented data. The augmented dataset will be saved in this file.templates(list): List of templates(string) or conll file to be used for augmentation.generate_templates(bool): if set to True, generates sample templates from given ones.show_templates(bool): if set to True, displays the used templates.
data_kwargs = {
"data_source" : "conll03.conll",
}
openai.api_key = "YOUR OPENAI KEY"
harness.augment(
training_data=data_kwargs,
save_data_path='augmented_conll03.conll',
templates=["The {ORG} company is located in {LOC}"],
generate_templates = True,
show_templates = True,
)